AI-powered workflows for math teaching and research
About a year has passed since I became interested in integrating AI tools into my work tasks (predating the GPT-4 hype by several months). Over time, I have developed several workflows around math teaching and research that could be useful for my colleagues. With the help of these workflows, I experience a significant speedup of many mundane tasks. I describe my tools and workflows here.
Table of contents
0. List of tools
Here is the list of tools I use more or less daily:
- Wolfram Mathematica — the famous software for symbolic computation. My university thankfully provides it (they tried to stop this over the summer, but got a massive backlash from math and physics - hopefully, they will continue picking up the apprently massive price tag).
- VScode with LaTeX workshop. I run it locally, but I think one can also use them in the cloud in the browser. As someone who also likes VIM, I need the ability to switch between VIM and other editors on the fly. This can be done locally.
- Overleaf for math collaboration (instead of Dropbox); my university pays for the premium version. I download the files locally using git, and can push my changes back to Overleaf (it acts as a git server).
- Mathpix Snipping Tool, an OCR which can recognize math and output LaTeX code ($5/month). I only pay for it when teaching - the free academic plan has 20 snapshots per month, which is enough when I don’t need to create problem sets.
- Alfred for Mac — a launchpad for Mac which allows you to create custom workflows. A “workflow” is typically a command that has some text as an input, and which runs a terminal command. A reddit thread with Windows analogues. If you use linux, you probably have something like that, too.
- heygpt — a simple command-line interface for OpenAI API. I use GPT-4 via the API key, which allows me to pay about $3-4/month instead of 20 for the web interface, and I can also pipelline it with other commands (they charge fractions of a cent for each request, depending on the length). This API only allows to use GPT-4 after your first bill; but for some of the tasks, GPT-3 is enough.
- GitHub copilot integrated into VScode (obviously, this requires internet connection). The copilot has free academic license, but approval time might be long. I think that these days copilot also uses GPT-4, but it is of course tailored for code (which includes LaTeX code).
- Grammarly premium, this is the most expensive item in my budget ($12/month). I use it integrated in VSCode (this is buggy, but corrects typos), and also I polish long prose segments in the web browser specially. This adds confidence to my writing.
So, my combined monthly spending on these tools is around $20, which is the same as the cost of just the single ChatGPT Premium subscription.
1. Teaching
1.1 Creating problems with solutions
To create a problem with solution for my undergrad probability course, I follow the steps:
- (optional) Use
mathpixto capture the problem from a textbook or an old exam - Paste the problem into
VSCode - Have
copilotautocomplete the solution
At the solution completion stage, the AI often outputs nonsense. The power of copilot vs, ChatGPT is that I can direct the AI solution step by step. Here is an example when I copy the problem from another exam. In this example, I have LaTeX compilation running in the background in terminal, to update the PDF automatically.
Often, copilot even tries to do computations for me, but fails miserably. Thus, I also need Mathematica to check computations. For that, I copy the latex code of an expression to compute, and ask GPT-4 to convert it to Mathematica code:
heygpt --model=gpt-4 "convert this expression to Mathematica, \
output just the mathematica expression \
\int_0^{\frac{1}{2}}\int_x^\infty 2\lambda e^{-\lambda y}\,dy\,dx " | tee >(pbcopy)
This request is automated through Alfred. I then copy the expression to Mathematica, and get the result. In the video below, even the step of the translation from LaTeX to Mathematica got wrong at the first try, since the order of integration got messed up. After noticing this and correcting, I got the right answer.
Here is a sample video of this workflow (sped up 2x):
2. Research
Below is just a sample of tasks where I use AI tools in my research. I am always on the lookout to automate more.
2.1 Tikz pictures
You can ask GPT-4 or ChatGPT to generate TikZ code for pictures. Here is an example with an early ChatGPT-4 (April 2023). It generated the tikz code for a picture using this request. After minimal modifications, I put it into a paper - Figure 5 on page 31 in arXiv:2305.17747:
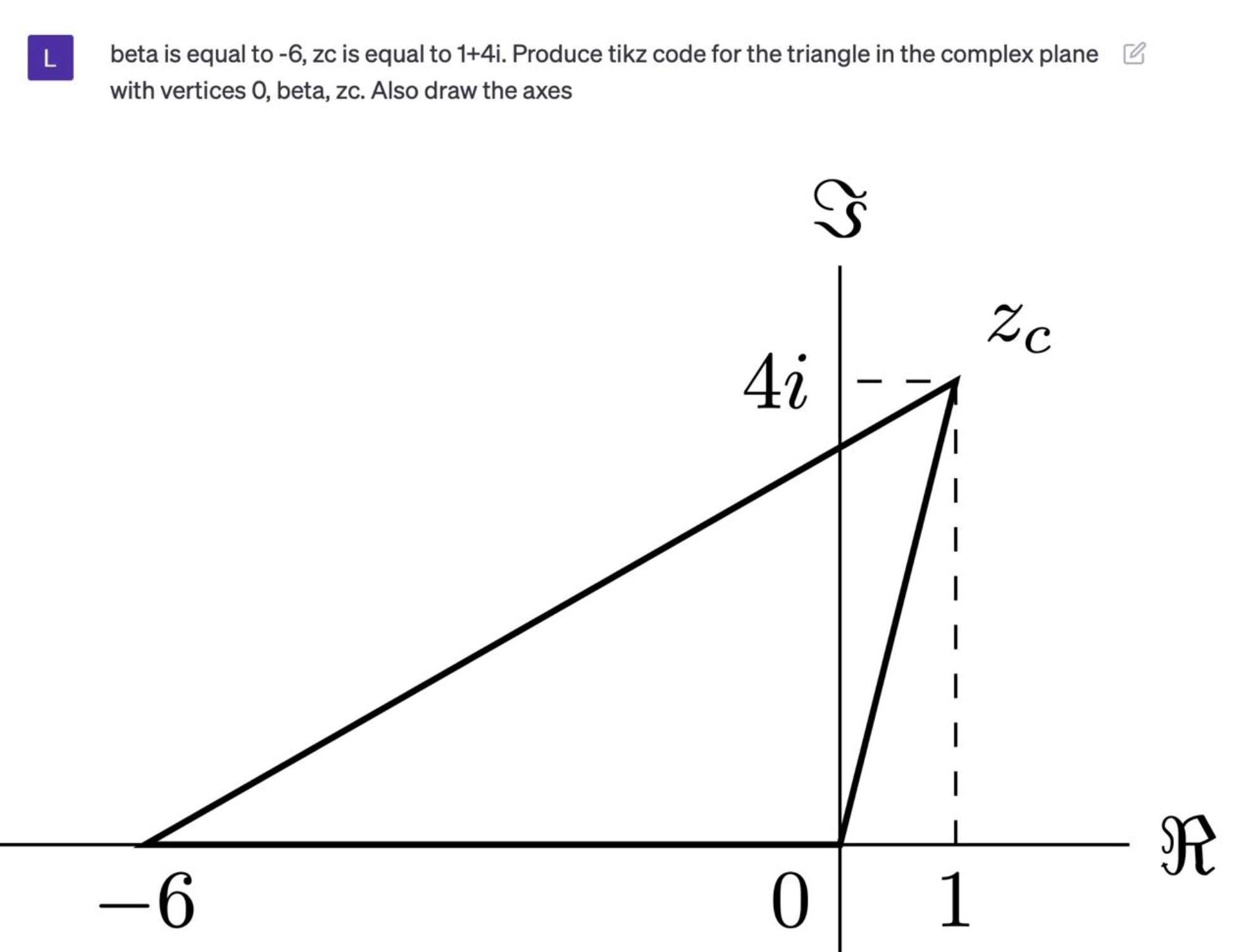
Unfortunately, this method can only generate rather simple pictures. For example, generate tikz code for an example of a six vertex configuration with domain wall boundary conditions does not produce anything meaningful, but generate tikz code for a 4 times 4 dotted grid with axes (t,x) labeled and a red line from (0,0) to (1,1) works reasonably fine. Moreover, it can modify your existing TikZ pictures on the fly, like changing notation in a complicated table of vertex weights. For this I would use a free-form input from a file workflow, see Section 3.3 below.
2.2 Translate LaTeX to Mathematica and back
Mathematica can output any of its results in LaTeX using the option TeXForm. However, sometimes this output is not pretty and I can ask GPT-4 to make it better (for example, remove \left and \right braces unless this is strictly needed; organize factors in a large product such that they look like 1-q instead of -q+1, and so on). Here is an example of not fully polished Mathematica output from a 2015 paper arXiv:1502.07374 (pages 26-27). I would prefer 1-q^J instead of q^J-1, but got lazy to fix this manually:
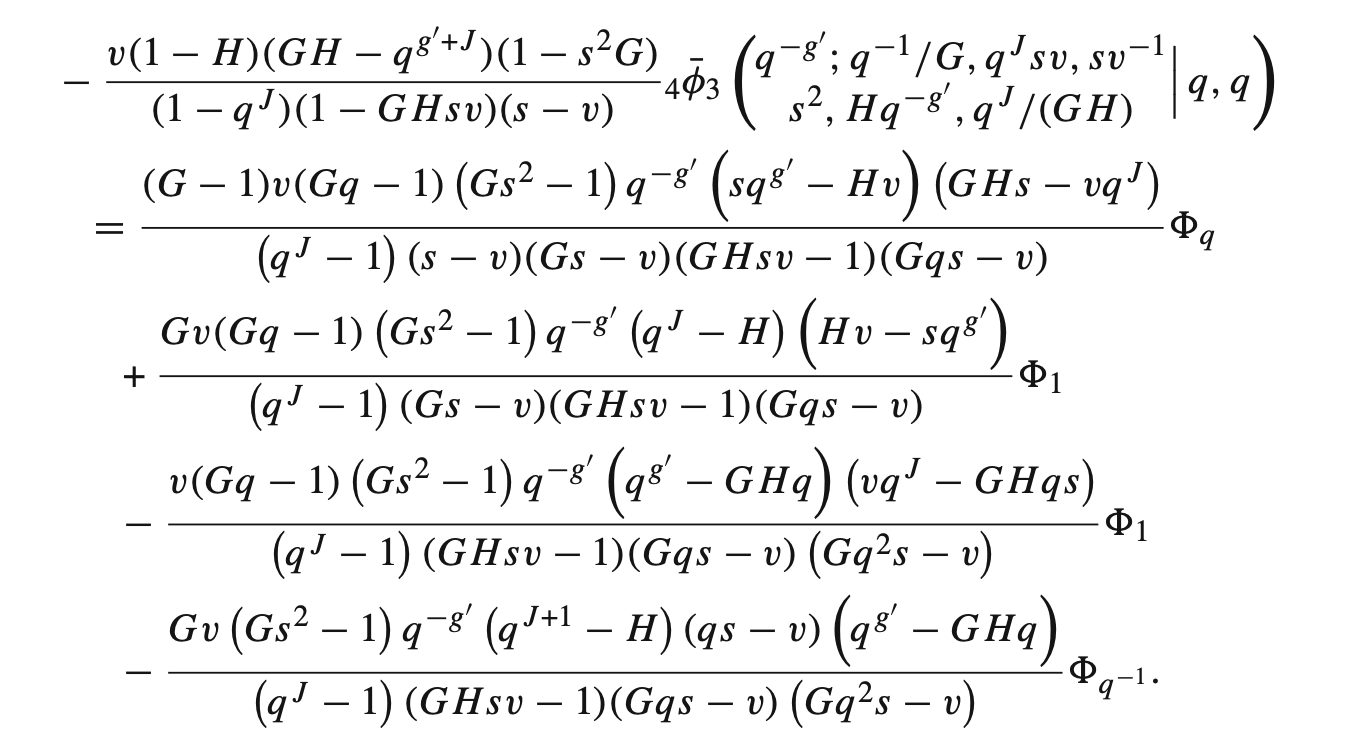
In another direction, translating from LaTeX to Mathematica was not generally avaiable to me until AI tools. Now, I can copy a piece of LaTeX code from a paper I currently write, and check in Mathematica that I did not make any typos. Better yet, I can snap a piece of code from a PDF of any paper I find, and use it for Mathematica computations.
In this example, I look at arXiv:0905.0679, pick the formula for the weight w(x) from Section 4, and check that the expression for w(x+1)/w(x) given in Section 8.2 is indeed correct.
Here is the GPT-4 API prompt for the second part of this task, where there is a typo in OCR w_{t, S}( & +1) / w_{t, S}(x), but GPT-4 does not care, and still produces a decent output:
heygpt --model=gpt-4 "convert this expression to Mathematica, output just the mathematica expression\
$\begin{aligned} w_{t, S}( & +1) / w_{t, S}(x)=\frac{q^{2 N+T-1}\
\left(1-\kappa^2 q^{2 x-t-S+3}\right)}{1-\kappa^2 q^{2 x-t-S+1}}\
\\ & \times \frac{\left(1-q^{x-t-N+1}\right)\left(1-q^{x-S-N+1}\right)\
\left(1-\kappa^2 q^{x-T+1}\right)\left(1-\kappa^2 q^{x-t-S+1}\right)}\
{\left(1-q^{x+1}\right)\left(1-q^{T-S-t+x+1}\right)\left(1-\kappa^2 q^{x+N-t+1}\right)\
\left(1-\kappa^2 q^{x+N-S+1}\right)}\end{aligned}$" | tee >(pbcopy)
There are of course manual caveats:
- I needed to remove the part related to
w_{t, S}( & +1) / w_{t, S}(x)=from the Mathematica output - The symbol
NinMathematicais protected, so I need to replace it withNNmanually.
Full video of the example is below. It is sped up 2x:
2.3 Bibliography entries
For bibliography, I maintain a giant bibtex file. For many years, I used google scholar bibtex export feature, but it is imprecise:
- I need to add arXiv number (I like to include them when available)
- The title of the paper should be wrapped in double braces, so that capitalization is correct
- I like to abbreviate first names of the authors, and
google scholaris doing it inconsistently
Recently, I stopped using google scholar’s bibtex export, and instead wrote my own bibtex prompt. Basically, I give GPT-4 several examples, and add the info about the paper from two sources which I copypast from the web: arXiv and the journal website. Here is an example of an Alfred workflow which generates and executes a request to GPT-4:
condition="I want you to make bibtex files in a format, from the data provided.\
Here are examples of my bibtex entries, use this format.\
IMPORTANT: 1. Abbreviate first names of authors, and journal names.\
2. Also, use double curly brackets around title. 3. Remove any month entries.
After END EXAMPLE I will give you data, output only bibtex entry for this data.
BEGIN EXAMPLE
@article{ayyer2022modified,
author = {Ayyer, A. and Mandelshtam, O. and Martin, J.B.},
journal = {arXiv preprint},
note = {arXiv:2209.09859 [math.CO]},
title = {{Modified Macdonald polynomials and the multispecies zero range process: II}},
year = {2022}}
@article{Baxter1972,
author = {Baxter, R. J.},
doi = {10.1016/0003-4916(72)90335-1},
journal = {Annals of Physics},
number = {1},
pages = {193--228},
title = {{Partition function of the Eight-Vertex lattice model}},
volume = {70},
year = {1972}}
@article{onsager1931reciprocal,
author = {Onsager, L.},
journal = {Phys. Rev.},
pages = {405},
publisher = {American Physical Society},
title = {{Reciprocal Relations in Irreversible Processes. I.}},
volume = {37},
year = {1931}}
<...A FEW MORE EXAMPLES...>
END EXAMPLE
remember: IMPORTANT: Abbreviate first names of authors, and journal names.\
Also, double curly brackets around title. And no month entries please.\
I just need the bibtex entry as output, and no comments.
"
e_condition=${(q)condition}
combined_query="${e_condition} {query}"
heygpt --model=gpt-4 "$combined_query" | tee >(pbcopy)
Here is an example of the input as {query} to the above script. These are just copypastes of pieces from the journal webpage and arXiv:
Home Probability Theory and Related Fields Article
Published: 30 March 2013
Macdonald processes
Alexei Borodin & Ivan Corwin
Probability Theory and Related Fields volume 158, pages225–400 (2014)Cite this article
2990 Accesses
264 Citations
Metricsdetails
arXiv:1111.4408 [math.PR]
You see that this text has lots of garbage data. But ran through the above prompt, this becomes the following bibtex entry:
@article{BorodinCorwin2014,
author = {Borodin, A. and Corwin, I.},
journal = {Prob. Theory Relat. Fields},
note = {arXiv:1111.4408 [math.PR]},
pages = {225-400},
title = {{Macdonald processes}},
volume = {158},
year = {2014}
}
2.4 Import conference calendar into my calendar
When I go to a conference, I like to have its calendar in my icloud. This way, I can always check my watch to see what is the next talk. Conferences rarely provide .ics files or google calendars (which would be equally good), and one of the main reasons I see for this is that it’s a pain to nicely display a google calendar on the web. So, math conferences typically resort to one of two terrible things:
- Make a PDF of the schedule with
LaTeXtable, which is downloaded on click (and not displayed in browser) - Or, make a webpage with the schedule in an
htmltable
I do not know which one is worse for machine readability, but thanks to mathpix OCR and GPT-4, I can convert either of them into .ics, which I can then add to my calendar.
Here is the prompt which more or less works for this conversion:
heygpt --model=gpt-4 "Make ical code for this event.\
This is in San Francisco, CA time zone, Pacific time, winter, year is 2023.\
Output the ical code only. I need the most complete information about\
the event or multiple events. Here is the data to process: {query}" | tee >(pbcopy)
Then I copy the text from the PDF or the webpage using OCR, day by day, and ask to convert it to .ics. Here is an example video of how this works for one day of a random conference:
3. Miscellaneous
3.1 Writing
I usually do all my prose writing in VSCode. This includes grant and proposal writing, where I use copilot autocompletion to break the writing block. Then, I usually polish the final version of the text with Grammarly on the web, as it suggests readability improvements.
Here is an example of me writing a blog post (this one) in VSCode:
3.2 Answering to emails in VSCode
A large portion of writing is responding to emails. Would it be nice to have long autocomplete suggestions, much longer than what gmail offers? You can also load several emails at once, and use the available context to generate a response.
I have created an applescript shortcut (which I call from Alfred) which can export selected message(s) in the Mail.app to VSCode. Of course, I used GPT-4 to come up with the applescript code.
tell application "Mail"
set theMessages to selection
set theOutput to ""
set totalMessages to count of theMessages
repeat with i from 1 to totalMessages
set aMessage to item i of theMessages
set theOutput to theOutput & "Subject: " & subject of aMessage & return
set theOutput to theOutput & "From: " & (sender of aMessage) & return
set theOutput to theOutput & "To: " & ((address of to recipient of aMessage) as string) & return
set theOutput to theOutput & "Date: " & (date received of aMessage as string) & return
set theOutput to theOutput & "Content: " & content of aMessage & return
set theOutput to theOutput & "---------------------------------------------" & return
log "Processed message " & i & " of " & totalMessages
end repeat
return theOutput
end tell
Example usage, where I open Mail.app, select a message, and run the hotkey in Alfred. Then I write the response in VSCode. I can then just copy the result, and put it in the email as an answer (not shown in the video).
3.3 free-form questions for GPT-4
I have an Alfred workflow to ask GPT-4 arbitrary questions. This is often much faster than google, when I just need a simple information like
what is the hotkey to record screen on Macwhat is the best video format for webhow to convert video from .mov to .mp4
I also have a workflow to read the question from file, and copy the answer to the clipboard when GPT-4 is done. Here is the heygpt command for this
heygpt --model=gpt-4 `cat ~/GPT.txt` | tee >(pbcopy)
The | tee >(pbcopy) part is responsible for copying the output to the clipboard, while at the same time the terminal shows the output. Here is a sample usage, where I write a request into file GPT.txt, run the hotkey in Alfred, then topy the result into the same text file, ask for funnier jokes, and run the request again. In the video, hg is my alias for heygpt --model=gpt-4.
3.4 Summarize PDFs
I can summarize PDFs by cutting them into several chunks and sending the chunks separately to be summarized. The result is a subsequent summary of all chunks, which I can summarize later one more time to get a high-level overview.
This is achieved with this python script (loosely based on this script, with my modifications which include heygpt):
import sys
import subprocess
import fitz # This is PyMuPDF
from nltk.tokenize import sent_tokenize
from io import StringIO
def read_pdf(filename):
sys.stderr.write(f"Reading PDF file... {filename}\n")
context = ""
with fitz.open(filename) as pdf_file:
num_pages = len(pdf_file)
sys.stderr.write(f"Number of pages in PDF: {num_pages}\n")
for page_num in range(num_pages):
page = pdf_file[page_num]
page_text = page.get_text('text')
context += page_text
sys.stderr.write(f"Finished reading page {page_num + 1}/{num_pages}\n")
return context
def split_text(text, chunk_size=5000):
sys.stderr.write("Splitting text into chunks...\n")
chunks = []
current_chunk = StringIO()
current_size = 0
sentences = sent_tokenize(text)
for sentence in sentences:
sentence_size = len(sentence)
if sentence_size + current_size <= chunk_size:
current_chunk.write(sentence)
current_size += sentence_size
else:
chunks.append(current_chunk.getvalue())
current_chunk = StringIO(sentence)
current_size = sentence_size
sys.stderr.write(f"Created a new chunk. Total chunks so far: {len(chunks)}\n")
if current_chunk.getvalue():
chunks.append(current_chunk.getvalue())
sys.stderr.write(f"Total chunks created: {len(chunks)}\n")
return chunks
def heygpt_completion(prompt, model_name="--model=gpt-4-1106-preview"):
sys.stderr.write("Sending prompt to 'heygpt' subprocess...\n")
try:
result = subprocess.run(['heygpt', model_name], input=prompt, text=True, capture_output=True, check=True)
return result.stdout.strip()
except subprocess.CalledProcessError as e:
error_message = f"heygpt error: {e}\n"
sys.stderr.write(error_message)
return error_message
def summarize(document):
sys.stderr.write("Summarizing document...\n")
chunks = split_text(document)
summaries = []
for chunk in chunks:
prompt = "Please summarize the following text:\n" + chunk
sys.stderr.write("Sending chunk to be summarized...\n")
summary = heygpt_completion(prompt)
summaries.append(summary)
sys.stderr.write(f"Received summary for chunk: {len(summaries)}\n")
sys.stderr.write("Completed summarization of all chunks.\n")
return ' '.join(summaries)
if __name__ == "__main__":
if len(sys.argv) < 2:
sys.stderr.write("Usage: python script.py <pdf_filename>\n")
sys.exit(1)
pdf_filename = sys.argv[1]
try:
sys.stderr.write(f"Starting the summarization process for {pdf_filename}\n")
document = read_pdf(pdf_filename)
summarized_content = summarize(document)
print("Final summarized content:\n")
print(summarized_content)
except FileNotFoundError:
sys.stderr.write(f"File '{pdf_filename}' not found.\n")
except Exception as e:
sys.stderr.write(f"An error occurred: {e}\n")
3.5 MSC classification
If I need to look up MSC2020 (Math subject classification) codes by code, or have suggestions for such codes for an abstract of a paper, I use the following heygpt prompt in Alfred:
hg "1. If the input is a code or a few codes, look up in the MSC 2020 (math subject classification database)
and output the descriptions of the codes.
2. However, if the input is a mathematical text, look up the MSC 2020 (math subject classification database)
and output suggested primary and up to 5 secondary MSC codes, with summaries.
Here is the input: {query}"
The output on the abstract of this recent paper is quite appropriate:
Primary MSC code:
- **60K35** (Interacting random processes; statistical mechanics type models; percolation theory):
This code would be appropriate since the paper focuses on stationary measures for interrelated particles
in systems from a probabilistic and statistical mechanics perspective.
Secondary MSC codes:
- **82B23** (Exactly solvable models; Bethe ansatz):
Since the paper mentions the use of integrable stochastic vertex models and the Yang-Baxter equation,
this code seems relevant.
- **82C22** (Interacting particle systems in time-dependent statistical mechanics):
The work is centered around interacting particle systems, like the mASEP, TAZRP, and q-PushTASEP,
making this code appropriate.
- **81R50** (Quantum groups and related algebraic methods):
The paper uses algebraic structures such as the Yang-Baxter equation, which is closely related to quantum groups.
- **60J27** (Continuous-time Markov processes on discrete state spaces):
If the paper discusses Markov processes for modeling the time evolution of the systems, this would be a fitting code.
- **05E05** (Symmetric functions and generalizations):
If the paper details connections with nonsymmetric Macdonald polynomials,
which are a generalization of symmetric functions, this code could be relevant.
And here is the output if I just ask Alfred to execute cmsc 60K35:
1. The code 60K35 from the MSC 2020 database corresponds to:
**60K35**: Interacting random processes; statistical mechanics type models; percolation theory
This area of mathematics concerns with random processes that have interaction terms
or dependencies between them, which are often analyzed using methods from statistical mechanics.
Examples might include processes such as Ising models, exclusion processes,
and various models of percolation. These models and theories help to understand how
the structure and behavior at a local level can affect the system's global properties,
often studying phenomena like phase transitions and critical behavior.